
When we talk with our trusted VL pioneers we often find them implementing timeline like applications, which come with the main problem to find the keyframe that is the closest to a given time, often even finding the two closest keyframes and interpolate between them weighted by the position of the current time.
Easy? Just order all keyframes by time and start at the first keyframe and go thru the collection until you find one that has a time greater than the time you are looking for. This is called linear search and might work very well at first, but obviously has two performance problems:
- The bigger the time you are looking for gets, the more checks you have to perform
- The more keyframes you have, the more checks you have to perform
Enter Binary Search
Binary search does the same task in a much smarter way: It starts with a keyframe in the middle of the collection and checks whether the time you are looking for is greater or smaller than this middle keyframe. Now it can rule out half of all keyframes already and search in the interesting half in the same way: Take the middle keyframe and compare its time. As this rules out half of all remaining keyframes in every step, the search is over very quickly. In fact it’s so stupid fast that on a 64-bit machine the maximum steps it has to perform is 64, because the machine cannot manage memory with more than 2^64 elements.
VL Nodes
The VL nodes cover several use cases. Depending on how your data is present you can choose from the following options.
Only Values
The most simple node is just called BinarySearch and takes a collection of values. It returns the element that is lower and the one that is higher, their indices and a success boolean indicating whether the search key was in the range of the input values at all:
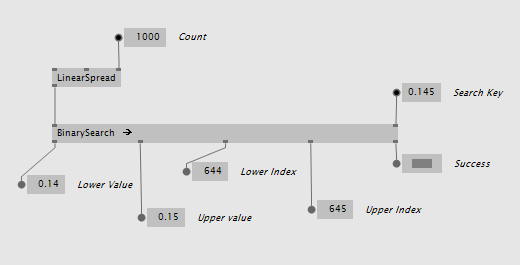
Key Value Pairs
For simple scenarios that don’t require a custom keyframe data type the BinarySearch (KeyValuePair) version can be used. It operates on the simple data type KeyValuePair that comes with VL.CoreLib and returns the values, keys and indices:
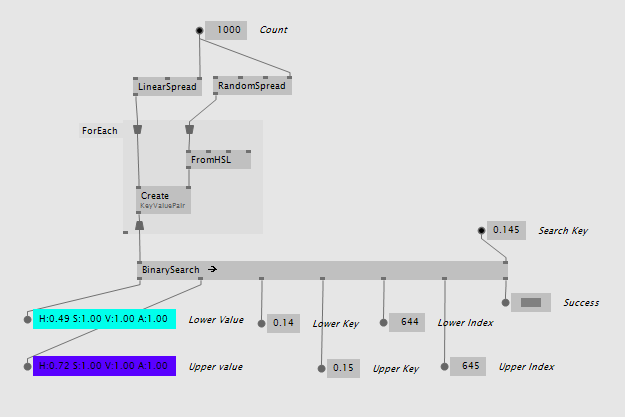
It also comes as BinarySearch (KeyValuePair Lerp) with an integrated linear interpolation between the values that is weighted by how far the search key is from the two found keyframes:
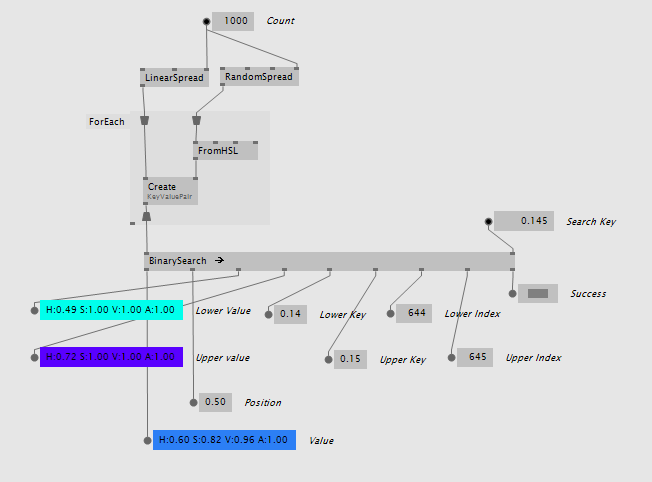
Custom Data Types
If you have your own keyframe data type the BinarySearch (KeySelector) is your friend. It can be created as a region with a delegate inside that tells the binary search how to get the key from your custom type:
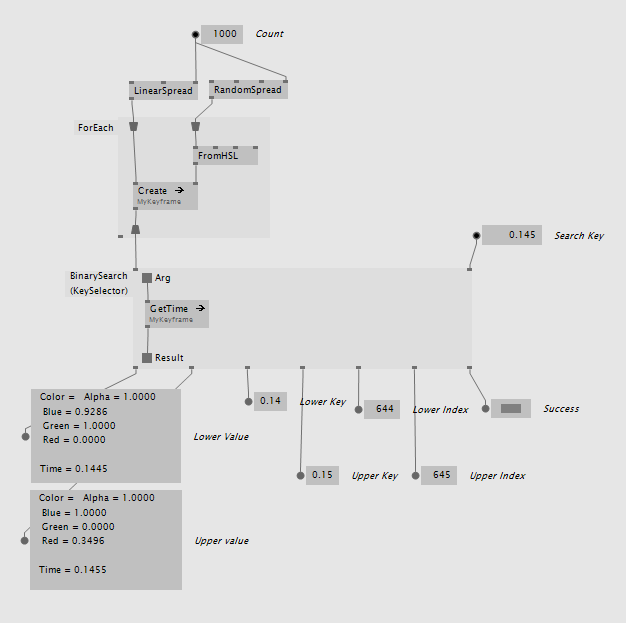
There is also BinarySearch (KeySelector Lerp) which has the same delegate and needs a Lerp defined for your keyframe that it can use internally. You keyframe data type could look like this:
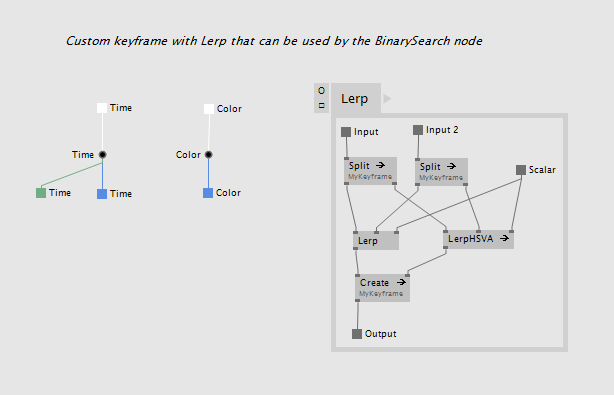
The usage is then basically the same:
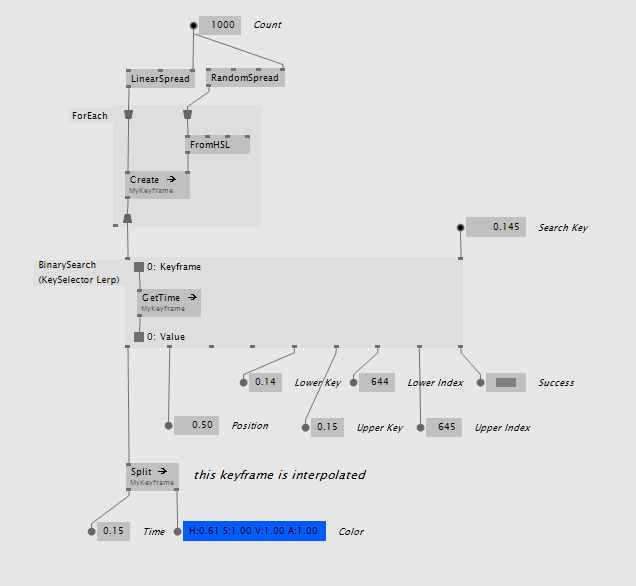
Other usages
A timeline is of course just one use case where binary search is useful. All data that can be sorted by a specific key can be searched by it. Speaking of sorting, if you add elements to a sorted collection binary search can help you to find the index at which to insert the new element. Use the Upper Index output as insert index like this:
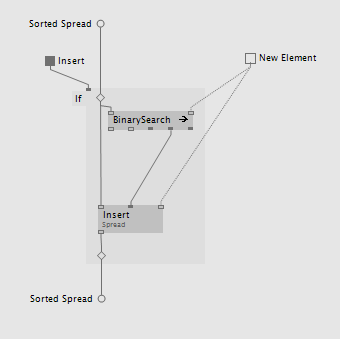
So it can help you to keep the very same collection up to date that you use to lookup the elements. A usage example can be found in girlpower\VL_Basics\ValueRecorder.
Enjoy the search!
Yours, devvvvs
Comments:
Comments are no longer accepted for this post.
any reason why you did not use the .net binarysearch ?
@u7angel, I think its cool that VL can do do this without having to know C#. I’m not that keen on scripting, though you are, and more power to your elbow, but I find it easier to follow a patch and reuse either nodes or whole patterns of coding than to learn C#. It seems appropriate to show users the power of the software they’ve developed with practical examples, wouldn’t you say? To my understanding, there shouldn’t be any particular performance difference between either method.
@tonfilm, how could these nodes be used to search through 2D or 3D points?
G
Not tested but will come close (and covers all the same edge cases I think):
Now, interesting part: what this does not do is give all the other outputs as nicely as the VL node, like Success and the other pins - that’s something that works well in VL but not so well (but still possible) in C#. Seems like when putting this node to VL we want to have these pins as well - and the patch that makes them is going to be a very simple one, using the C# implementation as its core.
and it’s not generic… i think a lot of features are missing from that code example.
but indeed, it’d be really interesting to see the exact same code in c#. i mean the whole patch with its 3 operations - maybe cleaned up before.
@u7angel it was an early exercise on how algorithms can be patched in VL. binary search was particularly interesting because it works very well together with basic VL features. our binary search implementation works on any collection that implements the IReadOnlyList which is most .NET collections including our Spread and SpreadBuilder and its super fast. so when using the .NET one you are limited to 2-3 collection types and of course you don’t want to copy a 50.000 element spread into a List just for binary search. so its about flexibility with the collection input as well as having flexibility with the element type, that the .NET ones don’t have at all.
That functionality is great to have.
However, I think making a patch like that a part of the corelib is a mistake:
That’s something you look at and go ‘holy shit that’s incomprehensible’! Don’t get me wrong: as a case study, this is great. If that is the best we can do, then I would suggest the outcome of this case study is that VL just isn’t good at lowlevel things like binary search. Too bad, but that seems to be the case. I would strongly suggest writing that up in C# and removing this from the corelib, having it in there 1) is daunting (even for me, much more so for newcomers) 2) encourages the bad practice of using VL for stuff VL is not good at.
hi @dominikKoller,
the messy looking part in that patch is there to catch corner cases and errors. so i disagree here, the core of the algorithm is quite beautiful in VL and proves that VL is much more than only a high level prototyping environment. if you are scared by it or you don’t understand that patch, just ignore it. and i strongly disagree in generalized statements like “VL just isn’t good at lowlevel things like binary search. Too bad, but that seems to be the case.” that’s simply not true and might confuse beginners.
however, i agree that it could be patched in a cleaner looking way by separating the parts of the algorithm into smaller operations.
You need to show us that, though. Everyone is looking at the patches you make to see if VL is any good! I guess all I want to say is that this current patch gives people (me inc) reason to believe that VL is not good at lowlevel things like binary search (whether true or not).
As for me, I need to see it before I believe it!
sebluser gave it a shot in the chat, just posting here to keep the discussion going.